华为 Atlas 800I A2 部署 Qwen2.5-32B 全栈 AI 应用实践
本文记录在鲲鹏+昇腾硬件上,基于 openEuler、vLLM-Ascend、Dify、RagFlow、Milvus 搭建大模型私有化知识库的完整过程,方便日后快速复现,记录一下。
环境概览
硬件:4×鲲鹏920_5250 处理器 + 8×昇腾910B NPU(Atlas 800I A2)
操作系统:openEuler 22.03 LTS SP4(aarch64)
关键软件:昇腾驱动/固件、CANN 8.5.0、torch-npu、vLLM-Ascend v0.13.0、Qwen2.5-32B-Instruct、Dify、RagFlow、Milvus
部署共分为六个阶段:基础系统准备、驱动与固件安装、CANN 软件包安装、Python AI 环境、vLLM 推理服务、应用平台搭建。
一、驱动和固件安装
先检查 NPU 状态:
#检查是否安装了驱动npu-smi info
如果未安装,需创建运行用户 HwHiAiUser 并准备编译环境:
#如未安装需安装,NPU驱动和固件安装用户,root安装,指定运行用户为HwHiAiUsergroupadd HwHiAiUseruseradd -g HwHiAiUser -d /home/HwHiAiUser -m HwHiAiUser -s /bin/bashyum makecacheyum install -y make dkms gcc kernel-headers-$(uname -r) kernel-devel-$(uname -r)
上传驱动和固件包后,添加可执行权限并安装:
chmod +x Ascend-hdk-910b-npu-driver_25.5.1_linux-aarch64.runchmod +x Ascend-hdk-910b-npu-firmware_7.8.0.6.201.run./Ascend-hdk-910b-npu-driver_25.5.1_linux-aarch64.run --full --install-for-all#结果:Driver package installed successfully!则安装成功./Ascend-hdk-910b-npu-firmware_7.8.0.6.201.run --full#结果:Firmware package installed successfully! Reboot now or after driver installation for the installation/upgrade to take effect 则安装成功
若指定非 root 运行用户,驱动安装时可添加
--install-username=<username> --install-usergroup=<usergroup>参数。安装完成后建议重启,但直接执行npu-smi info也可能已生效:#reboot 不用重启也行npu-smi info
二、通过 Docker 容器直接启动推理服务
此方式无需单独安装 CANN、torch、torch-npu、vllm 等组件,直接使用官方镜像 quay.io/ascend/vllm-ascend:v0.13.0。
参考链接:https://docs.vllm.ai/projects/ascend/en/v0.13.0/installation.html
Docker Compose 配置
编写 docker-compose.yml:
version: '3.8'services: vllm-ascend: image: quay.io/ascend/vllm-ascend:v0.13.0 container_name: vllm-ascend-env restart: unless-stopped # 可选,如需调试可改为 "no" network_mode: host # 使用宿主机网络,解决容器无法访问外网的问题 shm_size: 1g devices: - /dev/davinci0 - /dev/davinci1 - /dev/davinci2 - /dev/davinci3 - /dev/davinci4 - /dev/davinci5 - /dev/davinci6 - /dev/davinci7 - /dev/davinci_manager - /dev/devmm_svm - /dev/hisi_hdc volumes: - /usr/local/dcmi:/usr/local/dcmi - /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool - /usr/local/bin/npu-smi:/usr/local/bin/npu-smi - /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ - /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info - /etc/ascend_install.info:/etc/ascend_install.info - /root/.cache:/root/.cache # 缓存 Hugging Face 模型 # 可选:挂载宿主机上提前下载的模型目录(避免下载) # - /path/to/your/local/model:/models/Qwen2.5-32B-Instruct environment: - PYTORCH_NPU_ALLOC_CONF=max_split_size_mb:128 - VLLM_USE_MODELSCOPE=true - HF_HUB_OFFLINE=1 # 强制Hugging Face Hub处于离线模式[reference:8] - TRANSFORMERS_OFFLINE=1 # 强制Transformers库处于离线模式 - HF_HOME=/root/.cache/huggingface # 明确指定缓存根目录 - HUGGINGFACE_HUB_CACHE=/root/.cache/huggingface/hub # 明确指定Hub缓存目录[reference:9] command: > sh -c "vllm serve Qwen/Qwen2.5-32B-Instruct --tensor-parallel-size 8 --gpu-memory-utilization 0.85 --max-model-len 32768 --max-num-seqs 32 --enforce-eager" #容器启动自动执行运行,也可以进入容器后运行:vllm serve "Qwen/Qwen2.5-32B-Instruct"
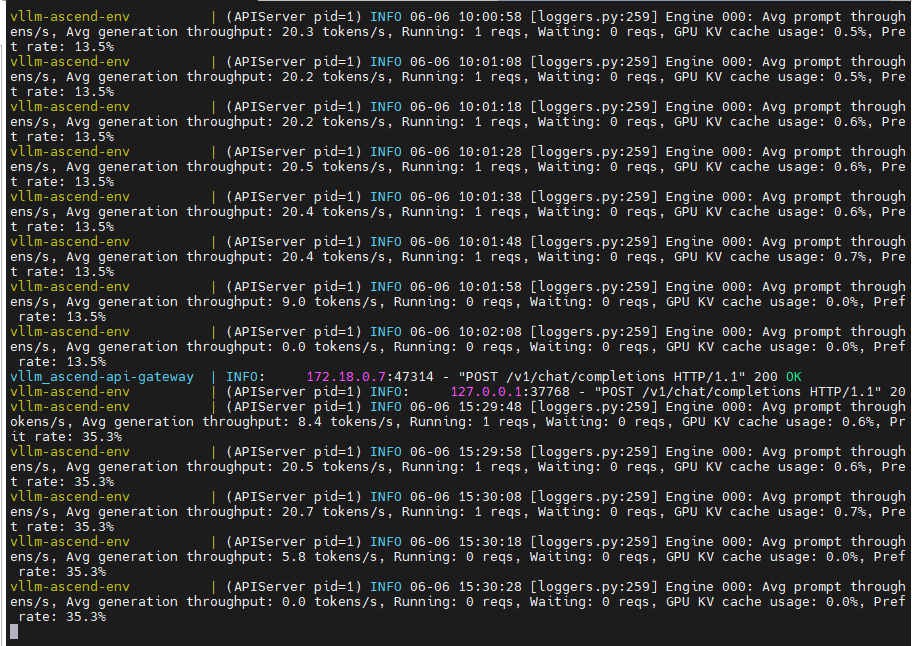
启动容器后,服务会监听 8000 端口,模型自动加载(若已离线缓存则直接使用)。
三、CANN Toolkit 安装(可选,物理机部署时使用)
若不走 Docker 方案,或者需要在宿主机进行开发调试,才需安装 CANN 开发套件。本次通过 Docker 启动,vllm-ascend 镜像已包含 CANN 运行时,因此以下步骤在本次方案中无需执行,仅作记录。
#cann toolkit 用root用户安装bash ./Ascend-cann-toolkit_8.5.0_linux-aarch64.run --install#安装ops算子包bash ./Ascend-cann-910b-ops_8.5.0_linux-aarch64.run --install#安装nnal加速bash ./Ascend-cann-nnal_8.5.0_linux-aarch64.run --install
配置环境变量(添加到 /etc/profile 实现开机生效):
source /usr/local/Ascend/cann-8.5.0/set_env.shsource /usr/local/Ascend/nnal/asdsip/set_env.sh
验证 CANN 安装:
python3 -c "import acl;print(acl.get_soc_name())"
四、大模型推理测试
容器启动后,可使用 curl 调用 OpenAI 兼容接口测试:
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen/Qwen2.5-32B-Instruct",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'正常应返回巴黎等回复。服务对外 API 地址为 http://192.168.2.104:8000/v1(根据实际 IP 调整)。
五、应用平台部署与归档指引
以下为生产环境中所有服务的启动方式及端口信息,适用两台机器(如 103、104)均如此操作。
1. Qwen2.5-32B 大模型启动
cd /data/vllm-ascend docker-compose up -d
2. 测试接口
#测试
curl -X POST "http://localhost:8000/v1/chat/completions" \
-H "Content-Type: application/json" \
--data '{
"model": "Qwen/Qwen2.5-32B-Instruct",
"messages": [
{
"role": "user",
"content": "What is the capital of France?"
}
]
}'API Endpoint:
http://192.168.2.104:8000/v1
3. Milvus 向量数据库
通过 docker-compose 启动:
cd /data/Milvus docker-compose up -d
服务端口:9091
4. Dify(华为适配版)
使用 KunpengRAG 项目中的部署文件:
# git clone https://gitee.com/kunpeng_compute/KunpengRAG.git 这个项目有华为 适配dify、ragflow、openwebui等项目 cd /data/KunpengRAG/deployment/docker-compose/dify docker-compose up -d
访问地址:http://192.168.2.104(首次使用需注册)
5. RagFlow(华为适配版)
为避免 MinIO 端口冲突,已修改为 19001、19000:
cd /data/KunpengRAG/deployment/docker-compose/ragflow docker-compose up -d
访问地址:http://192.168.2.104:8080(首次使用需注册)
结语